Although Perl makes it very easy to create, extend, or otherwise modify arrays, that doesn’t mean that a Perl array is the best way to store and search data. Not only do large arrays use up a lot of extra memory for each element (for an in-depth discussion, see the “Tie” chapter in Mastering Perl), but you don’t want to repeatedly traverse many arrays looking for what you’re after.
For this Item, consider that you have some task to look up things quickly across many, many records. Suppose the you have a list of possible terms that might be in a particular record, say, a list of keywords for a particular webpage. That’s a manageable example, but keep in mind real-world cases like all of the words in a novel or a scientific paper, or all of the actors in every movie. No matter the topic, your goal is to find each record where a particular word, actor, or whatever appears.
To see how it all works, you need a short example. Here’s a small corpus for your keyword example, stored as the values of anonymous arrays in a hash. For this Item, call the keys “records” and the elements of each array “terms”:
my %records = ( page1 => [ qw( dog collar legal ) ], page2 => [ qw( dog food diet ) ], page3 => [ qw( cat food medicine ) ], page4 => [ qw( dog medicine flea ) ], page5 => [ qw( dog flea collar ) ], );
How do you search the hash if you want to find all of the records that have both “dog” and “collar”? Your first and simplest code might be to just go through each record to look for those terms:
my @found;
foreach my $key ( keys %records ) {
my $value = $records{$key};
if( ... ) {
push @found, $key;
}
}
There are a couple of things wrong with this simple try, even if the problems don’t show up for such a small data size. It’s terribly inefficient for many records or many terms (or many records with many terms). It’s also not as simple as it looks.
What goes in that if condition in the previous code? You don’t know how many terms you want to find ahead of time, so you might have to throw in another loop to go through each search term.
sub find_matches {
my @search_terms = @_;
foreach my $key ( keys %records ) {
my $value = $records{$key};
my $count = 0;
foreach my $term ( @search_terms ) {
$count++ if $term ~~ $value;
}
push @found, $key if $count == @search_terms;
}
return \@found;
}
Notice the use of the smart match operator (Item 23. Make work easier with smart matching.) to see if $term is an element of the anonymous array $value.
Even though this can work, look at what you are doing. Every time that you want to search for terms, you might have to go through all of the terms and all of the records (the smart match doesn’t necessarily have to check every term), and you choose records by making string comparisons. Imagine doing that for big data. That’s a lot of work.
To avoid Perl doing all the work, you have to do a little more work yourself.
Pre-compute what you can
One of the strategies to solve this problem is to do some work up front so you don’t have to do so many comparisons later. If you know the list of all possible terms, you can create a packed structure that represent the presence or absence of that term in each record. It helps to think of your data as a spreadsheet:
| dog | collar | legal | food | diet | cat | medicine | flea | |
|---|---|---|---|---|---|---|---|---|
| page1 | x | x | x | page2 | x | x | x | |
| page3 | x | x | x | |||||
| page4 | x | x | x | |||||
| page5 | x | x | x |
Instead of doing a lot of string comparisons to find the intersection of the records that you want, you just have to look for rows that have entries in the same columns. Since each column simply marks “present” or “absent” for each term for that record, you only have to check its boolean value.
And, since each term is reduced to a boolean value, and each record has several terms, you might already suspect that your next step is to turn those boolean values into a single string; something that might look this:
my $string = '11011000';
That string isn’t the easiest thing to deal with though. Perlers have mostly forgotten their C skills (and some may not even have ever developed them). It’s time to refresh some of those skills. We’re not going to explain in detail the bit operators (and perlop isn’t much help). The Wikipedia page for Bitwise operation is a decent introduction.
Create bitfields
A bitfield is a series of bits that you store together. In Perl, this means that you’ll store the bits in the same scalar. Each bit in the bitfield represents one thing. To manipulate and extract values from your bitfield, you’ll use bit operators.
In your bitfield, you say that a bit is set if it has a 1 in that position. In 11011000, reading from right to left, bits 4, 5, 7 and 8 are set. All of the other bits are unset.
From your list of all known terms, you need to assign each term a position in the bitfield. Looking at your spreadsheet, you assign “dog” position 0, “collar” position 1, and so on. The particular positions don’t matter as long as you know what the positions map to:
my %positions = qw( dog 0 collar 1 legal 2 food 3 diet 4 cat 5 medicine 6 flea 7 );
For this Item, you’ll deal with this static structure, but you can also build this %positions dynamically as you discover new terms. Their positions don’t really matter. In this example, you have eight terms (isn’t that convenient?)
For each term, you use bit-OR (the | operator, which you use as part of the |= assignment operator) to set it in the bitfield. Once you have the bitfield for each record, you store it in %indices, which is what you’ll use to search for records later:
my %records = (
page1 => [ qw( dog collar legal ) ],
page2 => [ qw( dog food diet ) ],
page3 => [ qw( cat food medicine ) ],
page4 => [ qw( dog medicine flea ) ],
page5 => [ qw( dog flea collar ) ],
);
my %bitfields;
foreach my $record ( keys %records ) {
my $bitfield = 0;
foreach my $term ( @{ $records{$record} } ) {
$bitfield |= ( 1 << $positions{$term} );
}
$bitfields{$record} = $bitfield;
}
To inspect %indices, you can use printf's %b format to display the bitfields:
foreach my $record ( sort keys %bitfields ) {
printf "%s => %b\n", $record, $bitfields{$record};
}
Remember to read from right to left:
page1 => 00000111 page2 => 00011001 page3 => 01101000 page4 => 11000001 page5 => 10000011
You might think that this seems to store quite a lot of extra information, having an extra hash, and you'd be right. You also have to remember, however, that you want speed and to get that you trade some memory to get it. In this case, you store it in memory, but you can also put this into a database or some other persistent solution.
Once you have all of that set up (and that might take some work, but it pays for itself later), you need to be able to create a mask that represents the terms that you want to find. Each bit position in the mask is unique to a particular term, just like in the bit strings for each record, and it uses the same positional mapping. You only set the bits positions in the mask for the combination of terms you need to find.
The reduce function from List::Util comes in handy because you want to bit-OR (|) each term's position into the mask. reduce takes the first and second items off the list and puts them into $a and $b, making the @array two elements shorter. It then replaces those two items with the single result of its block. That means that $a is always going to be the mask in progress, so you can cheat a little by prepending the list with the starting state of the mask, in this case 0. From then on, you bit shift the second item before you bit-OR it with the mask in progress:
use 5.010;
use List::Util qw(reduce);
our ($a, $b); # avoid 'used only once' warnings
my $search_mask =
reduce { $a | (1 << $b) }
( 0, map { $positions{$_} // () } @search_terms );
When you have the completed mask in $search_mask, you can now quickly search all of your records. You want to find the ones where the result of the bit-AND (&) of the record and the mask returns exactly the mask:
my @found;
foreach my $record ( keys %indices ) {
my $result = $indices{$record} & $search_mask;
push @found, $record if $result == $search_mask;
}
A picture makes it more clear. You have a successful match if the result of the bit-AND is the same as the mask. In this case, looking for "cat" and "food" in page3 succeeds because both the mask and the result have exactly the same bits set (and no more than that):
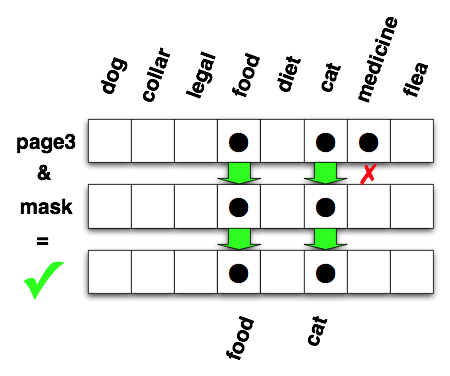
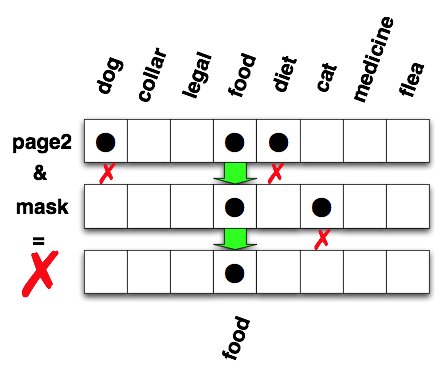
You don't have a successful match when the result of the bit-AND does not match the mask. Testing against page2 fails because "cat" is not set in both page2, so the bit-AND fails for that position and the corresponding bit is not set in the result. The result then is not the same as the mask:
Put it all together
Now you just have to put all of the pieces together. Here's the complete program which takes a list of search terms from the command line:
use 5.010;
use strict;
use warnings;
use List::Util qw(reduce);
my %records = (
page1 => [ qw( dog collar legal ) ],
page2 => [ qw( dog food diet ) ],
page3 => [ qw( cat food medicine ) ],
page4 => [ qw( dog medicine flea ) ],
page5 => [ qw( dog flea collar ) ],
);
my %positions = qw(
dog 0
collar 1
legal 2
food 3
diet 4
cat 5
medicine 6
flea 7
);
my %bitfields;
foreach my $record ( keys %records ) {
my $bitfield = 0;
foreach my $term ( @{ $records{$record} } ) {
$bitfield |= ( 1 << $positions{$term} );
}
$bitfields{$record} = $bitfield;
}
my $found = find_matches( @ARGV );
say "Found: @$found";
sub find_matches {
my @search_terms = @_;
# create the mask
our( $a, $b ); # avoid 'used only once' warnings
my $mask =
reduce { $a | (1 << $b) }
( 0, map { $positions{$_} // () } @search_terms );
# use the mask
my @found = ();
foreach my $record ( keys %bitfields ) {
my $result = $bitfields{$record} & $mask;
push @found, $record if $result == $mask;
}
return \@found;
}
This shows the basics of the technique, but it's a bit limited because you rely on Perl's built-in bit operations, which rely on the underlying architecture for their range. You can't, for instance, use more bits than you have in a native integer. Try it yourself to see the bits roll around:
foreach ( 30 .. 40 ) { # maybe your integers are bigger
printf "%2d: 0b%040b\n", $_, 1 << $_;
}
Make longer bitfields
Although by using Perl's bit operations you saw the mechanics of the technique, now that you know that you can forget about it and use the Bit::Vector module that comes with Perl.
Instead of the C-style bit operations, you just tell Bit::Vector which positions to set:
$vector->Bit_On( $positions{$term} );
Replacing all the bit operations with Bit::Vector method calls is straightforward. You're doing the same things in the same places, but with an object instead of Perl operators, and you're doing it with arbitrarily long vectors:
use strict;
use warnings;
use Bit::Vector;
my %records = (
page1 => [ qw( dog collar legal ) ],
page2 => [ qw( dog food diet ) ],
page3 => [ qw( cat food medicine ) ],
page4 => [ qw( dog medicine flea ) ],
page5 => [ qw( dog flea collar ) ],
);
my %positions = qw(
dog 0
collar 1
legal 2
food 3
diet 4
cat 5
medicine 6
flea 7
);
my %indices;
foreach my $record ( keys %records ) {
my $vector = Bit::Vector->new( scalar keys %positions );
foreach my $term ( @{ $records{$record} } ) {
$vector->Bit_On( $positions{$term} );
}
$indices{$record} = $vector;
}
my $matches = find_matches( @ARGV );
print "matches: @$matches\n";
sub find_matches {
my @search_terms = @_;
my $mask = Bit::Vector->new( scalar keys %positions );
my $intersection = $mask->Shadow;
foreach my $term ( @search_terms ) {
next unless exists $positions{$term};
$mask->Bit_On( $positions{$term} );
}
my @found;
foreach my $record ( keys %indices ) {
$intersection->And( $mask, $indices{$record} );
push @found, $record if $intersection->equal( $mask );
}
return \@found;
}
This program does the same thing as the previous version and gives the same output.
Reverse the index
So far, you've indexed each resource to create a bitfield the represents the terms in each of your pages. Since you did it that way, you end up searching through every page to see if it has the term you want to find. That's a lot of wasted work.
Instead of creating a bitfield of that represents the terms in each of your pages, you could invert the index so you create a bitfield that represents each of the pages that has the term. You can carry over some of the previous program, but the indexing is a bit fancier:
use 5.010;
my %records = (
page1 => [ qw( dog collar legal ) ],
page2 => [ qw( dog food diet ) ],
page3 => [ qw( cat food medicine ) ],
page4 => [ qw( dog medicine flea ) ],
page5 => [ qw( dog flea collar ) ],
);
my $empty = Bit::Vector->new( scalar keys %records );
my %reverse_indices;
my @records;
foreach my $record ( keys %records ) {
push @records, $record;
foreach my $term ( @{ $records{$record} } ) {
$reverse_indices{$term} //= $empty->Shadow;
$reverse_indices{$term}->Bit_On( $#records ); # last index
}
}
You create an empty (no bits set) bitfield that has one bit for each key in %records, and store that bitfield in $empty. That's the prototype bitfield you use for each index. When you need to initialize a new value for %reverse_indices, you call $empty->Shadow which gives you a new, empty bitfield of the same length. $empty should already be empty, so by calling Shadow you add suspenders to your belt.
In the foreach, you go through each record. There's an additional step here: you want to associate each record with a position in the bitfield so you can translate your results back to the pages that you found. Putting each key in @records does that nicely since you can use the array index as the bitfield position.
You use an inner foreach loop to go through all of the terms for each record. Inside the inner foreach loop, you initialize the value for that term if you haven't seen it previously then set the bit for the current record, which is really just the last index in @records.
Finding the matching pages turns out to look very much like what you saw previously in find_matches, although in this case you start with a full bitfield (all bits turned on) and bit-AND that with the index for each search term. The bit-AND operation only carries forward bits that are set in both bitfields, so the end result is
sub find_matches {
my @search_terms = @_;
my $pages = Bit::Vector->new( scalar keys %records );
$pages->Fill;
# return early if %reverse_indices doesn't have all the terms
foreach my $term ( @search_terms ) {
return [] unless exists $reverse_indices{$term};
}
foreach my $term ( @search_terms ) {
$pages->And( $pages, $reverse_indices{$term} );
}
my @found = $pages->Index_List_Read;
return \@found;
}
Notice that you can short-circuit the search too. The first foreach checks that each search term exists in the index. If any term in not in the index, there's no point going further because no collection of pages wil contain every search terms.
Once you've And-ed all of the bitfields for each search term, you call Index_List_Read to get a list of the positions that have bits set (although be careful with large bitfields because this could be a huge list!). Those values are the indices for the pages in @records that you built up earlier, so getting back to the page names you merely extract a slice with the right indices:
my $indices = find_matches( qw(dog collar) ); print "matches: @records[@$indices]\n";
Try it on something big
Now that you have the general idea, try creating an index for all of the words in the Perl documentation pages. The point isn't a high-quality index, so you don't need to worry about special cases in the text. The first thing that you need to do get a list of all of the pages and the words in them. Just work with all of the files in the pods/ directory in the Perl library directory.
You can use perldoc -l perlop to find that path, but that's no fun when you can kludge your way through Pod::Perldoc, which was designed to support a command-line program. You can set a local version of @ARGV to fake the command-line options and use Capture::Tiny to intercept the output since the module wants to print directly to standard output (unlike what we tell you in Item 55. Make flexible output.):
sub find_pod_dir {
use File::Basename qw(basename);
use Pod::Perldoc;
local @ARGV = qw( -l perlop );
my $perldoc = Pod::Perldoc->new;
my ($stdout, $stderr) = do {
use Capture::Tiny qw(capture);
capture { $perldoc->process };
};
chomp( $stdout );
my $pod_directory = dirname( $stdout );
}
Once you know where perl has its pod files, you can go through them to get all the words. It's the basic word counting program:
use File::Basename;
use File::Spec::Functions qw(catdir);
my $dir = find_pod_dir();
my %records;
foreach my $path ( glob( catdir( $dir, '*.pod' ) ) ) {
my $words_array = get_all_words( $path );
( my $docname = basename( $path ) ) =~ s/\.pod\z//;
$records{$docname} = $words_array;
}
sub get_all_words {
my( $path ) = @_;
open my( $fh ), '<', $path or do {
warn "Skipping $path! $!\n";
return [];
};
my %words;
while( <$fh> ) {
next if /\A\s/; # don't index verbatim lines
$_ = lc;
foreach my $word ( split ) {
$words{$word}++;
}
}
return [ keys %words ];
}
Now you just have to hook it up to the indexing stuff that you've already seen:
use strict;
use warnings;
use Bit::Vector;
use File::Basename;
use File::Spec::Functions qw(catdir);
my $dir = find_pod_dir();
my $count;
my %records;
foreach my $path ( glob( catdir( $dir, '*.pod' ) ) ) {
my $words_array = get_all_words( $path );
( my $docname = basename( $path ) ) =~ s/\.pod\z//;
$records{$docname} = $words_array;
}
my $empty = Bit::Vector->new( scalar keys %records );
my %reverse_indices;
my @records;
foreach my $record ( keys %records ) {
push @records, $record;
foreach my $term ( @{ $records{$record} } ) {
unless( exists $reverse_indices{$term} ) {
$reverse_indices{$term} = $empty->Shadow;
}
$reverse_indices{$term}->Bit_On( $#records ); # last index
}
}
my $results = find_matches( map lc, @ARGV );
{
local $" = "\n\t";
print "results for [@ARGV] are\n\t@records[ @$results ]\n";
}
sub get_all_words { ... same as before ... }
sub find_pod_dir { ... same as before ... }
sub find_matches {
my @search_terms = @_;
my $pages = Bit::Vector->new( scalar keys %records );
$pages->Fill;
foreach my $term ( @search_terms ) {
unless( exists $reverse_indices{$term} ) {
warn "The terms [@search_terms] aren't in the index\n";
return [];
}
$pages->And( $pages, $reverse_indices{$term} );
}
my @found = $pages->Index_List_Read;
return \@found;
}
Now you can find words in the documentation:
$ perl perldoc_indexing vector
results for [vector] are
perlglossary
perl561delta
perlfunc
perlfaq4
perldiag
perl56delta
perl5004delta
perlothrtut
perltoc
perlthrtut
You can improve this program by saving the result of the word counting so you don't have to redo that work every time.
Find similar pages
Take this one step further. Instead of looking for records that have the right terms, look for pages that have terms in common. You don't need a mask for the search terms because the bitfield for a starting page is the mask. You bit-AND a particular page's bitfield to all of the other pages' bit fields instead.
However, instead of returning pages that match, you can compare the number of bits in the intersection to the number of bits in the starting page. For every other page, you store not just the page number, but the ratio of set bits in common to the set bits in the starting page:
# with setup from previous programs
my $similar = find_similar_pages( $ARGV[0] );
foreach my $tuple ( @$similar ) {
printf "%4.2f %s\n", @$tuple[1,0];
}
sub find_similar_pages {
my( $start_page ) = @_;
my $start_page_count = count_bits( $bitfields{$start_page} );
return [] unless $start_page_count;
foreach my $record ( keys %bitfields ) {
next if $record eq $start_page;
my $intersection = $bitfields{$record}->Shadow;
$intersection->And( $bitfields{$start_page}, $bitfields{$record} );
$bit_count = count_bits( $intersection );
push @similar, [
$record,
eval { $bit_count / $start_page_count } || 0
];
}
# Now sort by similarity
@similar = sort { $b->[1] <=> $a->[1] } @similar;
return \@similar;
}
sub count_bits { $_[0]->to_Bin =~ tr/1// }
Now the output is a sorted list of page similarity:
$ perl find-similar-pages page2 1.00 page9 0.67 page6 0.33 page4 0.33 page1 0.33 page7 0.33 page3 0.33 page5 0.00 page8
Once you see that, you might naturally be led to make a similarity matrix. Reusing parts of what you already have, instead of taking a page name from the user, you compute the similarity for all page pairs and store them in a two-level hash. Everything else is just formatting and output. Using Term::ANSIColor makes the output a bit easier to read:
my %similarity;
foreach my $first ( keys %indices ) {
foreach my $second ( keys %indices ) {
$similarity{$first}{$second}
= compute_similarity( $first, $second );
}
}
my @sorted_keys = sort keys %records;
printf "%5s " . ( "%6s" x @sorted_keys ) . "\n", '', @sorted_keys;
foreach my $record ( @sorted_keys ) {
printf "%5s " . ( " %6s" x @sorted_keys ) . "\n",
$record, map { with_color($similarity{$record}{$_}) } @sorted_keys;
}
sub compute_similarity {
my( $record1, $record2 ) = @_;
my $start_page_count = count_bits( $indices{$record1} );
return [] unless $start_page_count;
my $intersection = $indices{$record1}->Shadow;
$intersection->And( $indices{$record1}, $indices{$record2} );
$bit_count = count_bits( $intersection );
eval { $bit_count / $start_page_count }
}
sub with_color {
my( $value ) = @_;
require Term::ANSIColor;
my $color = do {
if( $value > 0.75 ) { 'cyan' }
elsif( $value > 0.50 ) { 'green' }
elsif( $value > 0.25 ) { 'bright_red' }
else { 'red' }
};
return Term::ANSIColor::colored( sprintf("%4.2f", $value), $color );
}
Now you can see at a glance which pairs of pages are the most similar:
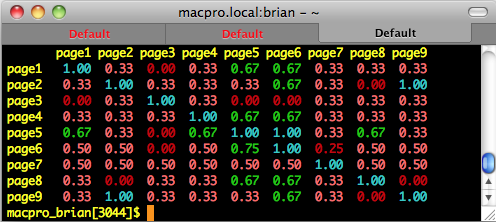
Notice that the matrix is not symmetric. It depends on which page is the starting page. Since each page might have a different number of terms, the denominator of the ratio depends on the terms of the starting page.
Use the right technique
You've seen two ways (at least) to pre-compute an index for fast lookups. One of them used the record names as keys and indexed the search terms, while the other used the possible search terms as the keys.
If you like, you can memoize find_matches and the other search subroutine so you only have to perform any particular search once and then reuse the results (as long as the records don't change in any way). You can even cache all of the results to reuse them in a later run.
Be careful with the code in this Item; it's just sample code to illustrate the ideas. We don't intend you to paste this code into your programs or to build around it as complete applications. Tailor the ideas to your situation.
Things to remember
- Use bitfields for to create fast lookups across multiple terms
- Create reverse indices to find similar records
- Use Bit::Vector to easily manipulate large bitfields